https://www.dbpia.co.kr/pdf/pdfView.do?nodeId=NODE09316907
DBpia
논문, 학술저널 검색 플랫폼 서비스
www.dbpia.co.kr
위 논문을 요약한 내용입니다
1. 서론
인공지능 및 IoT 4차산업기술의 발전과 함께 서비스 로봇 시장은 매년 성장할 것으로 예측된다
이동로봇의 자율주행 기술은 환경지도에서 로봇의 위치를 인식하고, 현재 위치로부터 목적지까지 이동경로와 방향을 결정하고 제어하는 기술을 지칭한다
실내에 비해 실외 이동로봇의 상용화가 더딘 이유
1. 기술적인 측면에서 실외 자율주행은 실내에 비해 보다 난이도가 놓고 고도화된 기술을 요구함
- 날씨, 계절, 시간 등의 조건에 따라 변동성이 커서 지도생성에 많은 시간과 노력이 필요
- 보행자와 같이 동적인 장애물이 많아 신뢰성 높은 자율주행 기술을 개발하는 것이 어려움
2. 규제의 문제
현행 도로교통법상 로봇은 ‘차’로 구분되어 보도 통행이 불가능하여 상용화를 위한 실증테스트가 어렵다.
- 대부분의 실외 배송로봇은 대학 캠퍼스나 아파트 단지 등 제한된 영역에서만 테스트
2. 로봇 위치인식(Localization)
- 로봇의 위치와 자세를 추정하는 기술로 자율주행의 가장 핵심이 되는 기술
- 실내 이동로봇의 경우 2차원 평면상의 위치와 자세값만 추정하면 되지만, 실외 이동로봇은 6자유도의 위치/자세 값을 추정해야 함
- 본 장에서는 실외 이동로봇의 위치인식을 위한 대표적인 방법인 3D SLAM (Simultaneous Localization and Mapping)과 GPS/odometry 융합방법에 대해서 살펴보고자 한다.
2.1 3D SLAM
- 실외 이동로봇에 적용되는 SLAM 기술은 사용하는 센서에 따라 LiDAR 센서기반 SLAM과 Vision 센서기반 SLAM으로 구분
<LiDAR based SLAM>
- LiDAR 기반 SLAM의 경우 LiDAR 센서로부터 수집된 3차원 점군 데이터를 이용하여 지도를 작성
- 휠 엔코더나 IMU 센서 등의 odometry 정보를 이용하여 로봇의 이동변위를 추정
- 이전위치와 현재위치에서 측정한 LiDAR 점군 데이터를 매칭하여 위치를 보정하는 방식
- 비교적 정확한 위치추정 성능(±5 cm 이내)을 제공
[대표적인 방식]
- EKF SLAM
- Particle Filter SLAM
- Fast SLAM
- Graph SLAM
한계점
1. 가격
2. 사전에 3D 점군 지도를 생성해야하는 문제가 있음
<Vision based SLAM>
- 카메라 영상정보를 이용하여 지도를 생성하고 이동로봇의 위치를 추정하는 기술
- 센서의 가격이 저렴
- 여러 로봇이 동시에 이동하더라도 센서 간의 간섭이 없음 (두 대의 LiDAR-based SLAM 로봇이 만나는 경우 고려)
- 영상정보를 위치인식 이외의 장애물 인식이나 환경인식에 사용할 수 있다는 장점
한계점
1. 카메라의 FOV가 제한되어 있어 빠른 움직임을 추정하는데 한계가 있음
2. LiDAR 기반 SLAM에 비해 정확도가 떨어짐
초창기 vision 센서기반 SLAM은 단일 카메라를 이용하여 영상내의 특징점들을 추척하고 이를 기반으로 지도생성과 위치 추정하는 방식에 기반함
ㄴ> Mono SLAM의 경우 연산량이 환경의 크기에 따라 증가하여 대형공간에서 실시간 위치 추정 어려웠음
ㄴ> PTAM, ORB-SLAM 등의 방법이 제안
ㄴ> 최근 RGB-D 카메라가 대중화되면서 이를 이요한 SLAM 기술들이 제안되고 있음
ㄴ> 하지만 RGB-D 카메라의 경우 깊이정보를 취득할 수 있는 범위가 10m 이내로 제한되어 생성되는 지도와 위치추정 성능도 이러한 사양에 제약이 있음
2.2 GPS/Odometry 융합 방법
실외환경에서 위치인식을 위해 가장 손쉽게 사용할 수 있는 센서는 GPS
GPS 단독으로는 이동로봇의 위치를 추정하는데 한계가 있음 -> (도심지역 건물 등의 장애물)
ㄴ> GPS의 문제점을 해결하기 위하여 이동로봇의 휠엔코더 혹은 IMU센서로부터 측정된 odometry 정보와 융합하는 방법들이 제안됨
ex) Kalman Filter, Extended Kalman Filter, Unscented Kalman Filter 등
위 방법은 가격이나 활용성 측면에서 강한 장점이 있지만, 위치추정 정확성과 신뢰성이 보장되지않아
LiDAR나 카메라 vision과 같은 추가의 센서와 융합하는 multi-modal 센서 융합기술이 필요함
3. 주행환경인식(Perception)
지도상에서 이동로봇의 전역위치를 인식한 후, 로봇이 이동하기 위해서는 주변 환경을 인식해야함
ㄴ로봇에 장착된 센서로부터 들어오는 raw data를 분석함으로써 주변환경을 인식하게됨
본 장에서는 기존의 여러 방법들 중 최근 주목을 받고 있는 딥러닝을 이용한 영상 기반 객체인식 방법과 주행가능영역 인식 방법에 대해 설명함
3.1 영상기반 객체 인식 기술
전통적으로 영상에서 객체를 인식하기 위하여 특징점 추출(SIFT, HOG, Haar-like features)이나 분류기(SVM, AdaBoost , Deformable Part-based Model)등의 방법들이 사용 -> 조명, 배경, 카메라 각도 등에 영향을 많이 받음
ㄴ> 2014년 R-CNN의 등장 (DNN 기반의 영상인식 방법)
R-CNN에서 객체를 인식하는 방법 3단계
1. 입력된 영상에서 2000개의 영역을 Selective Search 알고리즘을 통해 추출(region proposal)
2. 추출된 영역을 warping하여 CNN에 입력한 후 feature vector를 뽑아냄
3. feature vector를 SVM에 입력하여 객체를 분류
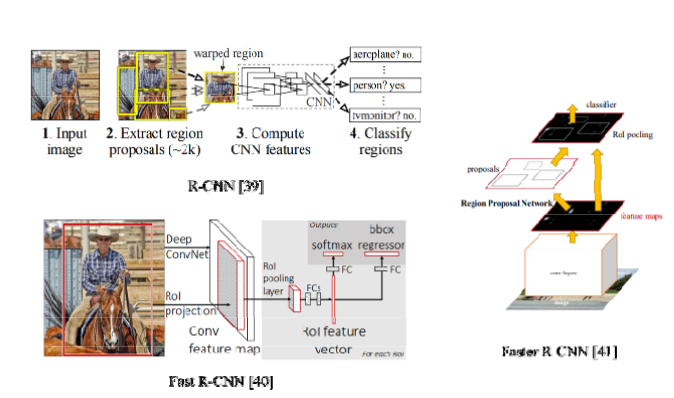
2000개의 후보영역을 개별적으로 처리해야 하기 때문에 연산량이 많다는 단점
ㄴ> Fast R-CNN : 전체 이미지와 ROI를 함께 CNN에 입력 -> ROI 벡터마다 특징 벡터를 추출 -> 객체 분류
결과 : 처리속도가 R-CNN 보다 약 10 배 빨라졌지만, 아직도 region proposal을 추출하는데 연산량이 많음
-> Faster R-CNN이라는 이름으로 Region Proposal Network(RPN)을 사용하여 연산량 줄이는 방법 제안됨
위에서 설명한 region proposal 기반 객체인식은 여러 단계를 거치기 때문에 연산량 줄이기 한계가 있었음
ㄴ> 픽셀에서 직접 해당 객체의 Bounding Box를 추출하는 방법 제안 ex) YOLO, SSD(Sing Shot Detector)
YOLO
-> 각 셀은 객체를 감싸는 BB를 2개씩 포함하고 셀에 해당되는 객체의 확률정보를 담고 있음
-> 학습된 CNN에 영상을 입력하면 각 셀의 정보가 출력
-> 학습된 CNN에 영상을 입력하면 각 셀의 정보가 출력
속도는 YOLO 정확도는 Faster R-CNN이 우위
SSD
Single Shot Detector는 YOLO와 마찬가지로 단일 CNN을 이용하여 객체를 인식하는 방법
속도와 정확성 측면에서 YOLO보다 우월
SSD 크기가 다른 여러 개의 객체를 한번에 검출하기 위하여 여러 크기의 특징 맵(feature map)을 사용
3.2 영상기반 주행영역 인식 기술
주행가능영역을 인식하기 위해서는 주행영역을 박스형태가 아닌 픽셀단위로 보다 정밀하게 추출해야함 -> Semantic sementation -> 객체인식기술보다 한 단계 진화된 영상인식 기술
Fully Convolutional Layer (FCN)
CNN을 이용한 semantic segmentation의 초창기 방법
CNN과 다르게 (CNN은 해당 이미지의 레이블에 대한 확률을 벡터 값으로 출력) FCN은 각 픽셀에서의 레이블 정보를 출력
ㄴ> FCN은 semantic segmentation을 위한 강력한 방법이지만, 컨텍스트 정보 반영X, 효율성이 떨어져 실시간성이 보장되지 않는다는 한계점 있음
ㄴ> Conditional Random Field (CRF), Dilated Convolution, Multi-scale Prediction등 처리속도와 정확도를 높이기 위한 여러 가지 방법들이 제안
Semantic segmentation을 하는데 있어서 한 가지 어려운 점 : 학습데이터를 확보하는 것
ㄴ 픽셀단위로 구분하는 semantic segmentation의 경우 학습데이터 역시 픽셀단위로 레이블이 되어야함 -> 이 과정에서 시간, 노력이 상당히 필요함
4. 경로계획 (Planning)
경로계획은 로봇의 현재위치에서 목적지 까지의 최적경로를 찾는 문제로 정의
1. 이동시간을 최소화하는 경로
2. 비용을 최소화하거나 안전을 최대화하는 경로
크게 전역 경로계획(Global path palnning)과 지역경로계획(Local path planning)으로 나눌 수 있음

4.1 전역경로계획 (이동로봇의 최종목적지까지의 경로를 계획)
첫 번째 단계 : 주어진 지도정보를 최적 경로 탐색에 적합한 형태로 변환하는 모델링이 필요
ex) Voronoi Graph[50], Tangent Graph [51], Visibility Graph [52] 등 framework space에 기반한 방법, 이동로봇의 주행가능영역을 convex 영역으로 정의하는 자유공간기법(free space approach) [53], 그리고 영역을 형태가 균일한 셀로 나누는 셀 분할기법(cell decomposition approach) [54] 등이 제안
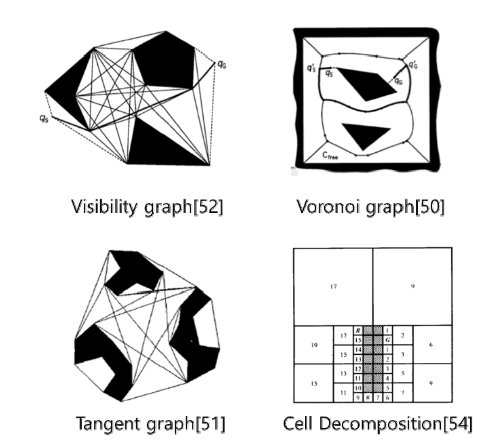
두 번째 단계 : 최적화 기준을 선정 -> 경로의 길이, 경로의 smoothness, 안전의 정도와 같은 기준 적용
최적경로 알고리즘으로는 휴리스틱에 기반한 Dijkstra 알고리즘, A* 알고리즘, D* 알고리즘,
AI에 기반한 ANN (Artificial Neural Network), GA (Genetic Algorithm), ACO (Ant Colony Optimization), PSO (Particle Swarm Optimization) 알고리즘 등이 있음
4.2 지역경로계획 (이동하는 중에 장애물과 같은 이벤트가 발생하였을 경우 일부 경로를 수정하는 역할)
대표적인 방법
- Artificial Potential Field
- Behavior Decomposition
- Case-based Learning
- Rolling Window Algorithm
최근에는 딥러닝 학습방법을 이용하여 보행자나 장애물들의 이동패턴을 반영하여 보다 능동적으로 회피하는 지역경로계획 방법에 대한 연구들이 진행
느낀점
국내논문을 처음 정독하면서 읽어봤는데
알고 있던 내용들도 잘 정리된 글로 보니 리마인드하기 좋았다
내가 알고 있는 내용을, 글을 통해 독자들에게 잘 전달하는 능력을 갖고 싶다고 생각했다
컨트리뷰션 논문이 아닌 서베이 논문을 시작으로 논문과 친해져서 동향을 파악한다음,
흐름을 읽고 따라서 차차 신진기술 연구 논문들을 읽어봐야겠다
끝