반응형
Lecture7 Traning Neural Networks
Contents
Fancier optimization
Regularization
Transfer Learning(전이학습)
SGD 방식의 문제

- SGD는 학습률이 고정되어있어 최적화가 비효율적임
- 학습률이 변화할 수 있다면 처음에 큰 폭으로 이동하다가 최적해에 가까워질 수록 이동폭을 줄여서 안정적으로 수렴가능
- 학습률이 변화할 수 있다면 처음에 큰 폭으로 이동하다가 최적해에 가까워질 수록 이동 폭을 줄여서 안정적으로 수렴할 수 있음
- SGD는 결국 local minima와 saddle point에 빠지기 쉽다(위 local minima, 아래 saddle point)
- 경사가 완만하면 큰 폭으로 이동하는게 좋고, 경사가 가파를 때 천천히 이동하는게 좋음
SGD Momentum
- SGD 모멘텀은 기존 SGD에서 관성을 주어 느린 학습 속도와 협곡과 안장점을 만났을 때 학습이 안되는 문제, 거친 표면(일관적이지 않은 학습)에서 진동하는 문제를 해결한 최적화 알고리즘
- 그레디언트 벡터는 현재 위치에서 가장 가파른 방향
- 속도 벡터는 현재 이동속도
- SGD 모멘텀은 현재 속도 벡터 + 그레디언트 벡터를 더해서 다음 위치를 정함

- 다음 속도는 현재속도와 마찰계수와 곱한 후 그레디언트를 더해서 계산(p = 마찰계수로 0.9~0.99로 지정)
오버슈팅 문제
- 경사가 가파른 경우 빠른 속도로 내려오다가 최소 지점을 만나면 그레디언트는 순간적으로 작아지지만, 속도가 여전히 커서 최소 지점을 지나는 현상
- 최소 지점이 평지 위에 있으면 오버슈팅 발생 x
- 최소 지점 주변 경사가 가파른 경우 속도가 커서 오버슈팅이 발생할 수 있음
- 해결방법 : 최적 해 주변을 평평하게 만들어 주는 정규화 기법 사용
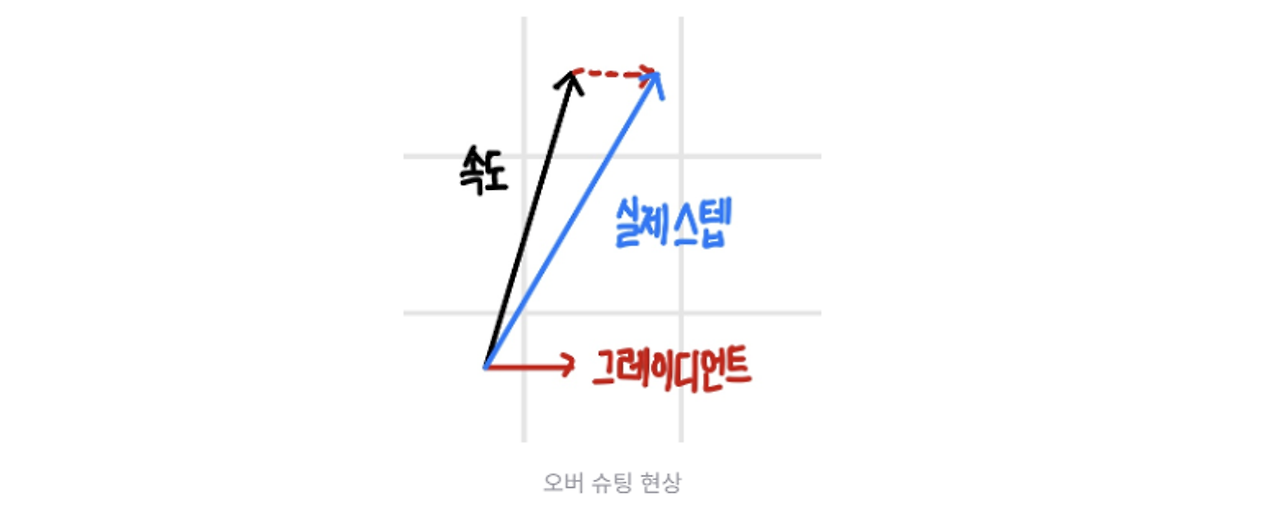
네스테로프 모멘텀
- SGD 모멘텀과 동일하게 진행 속도에 관성을 줌, 오버 슈팅을 막기 위해 현재 속도로 한 걸음 미리 가보고 오버슈팅이 된 만큼 다시 내리막길로 내려감
- 한걸음 미리 갔을 때 높이 올라간 만큼 다시 내려오도록 그레디언트 교정
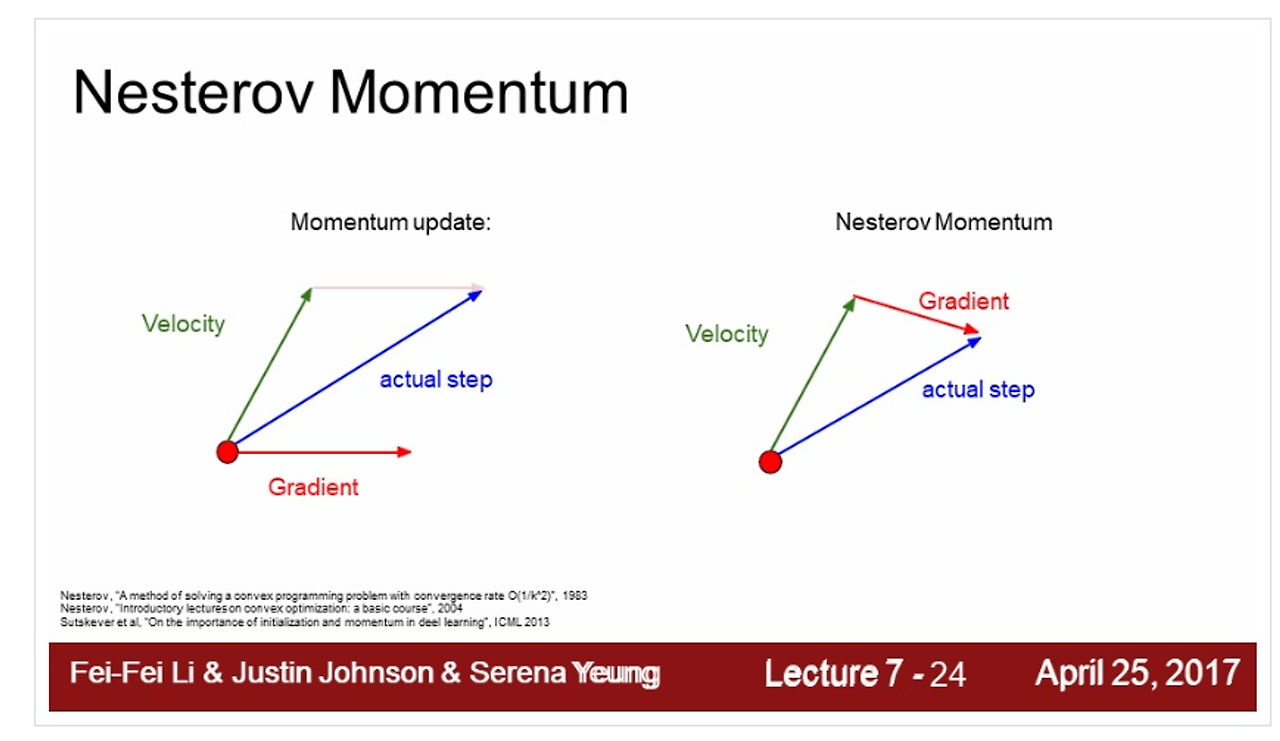

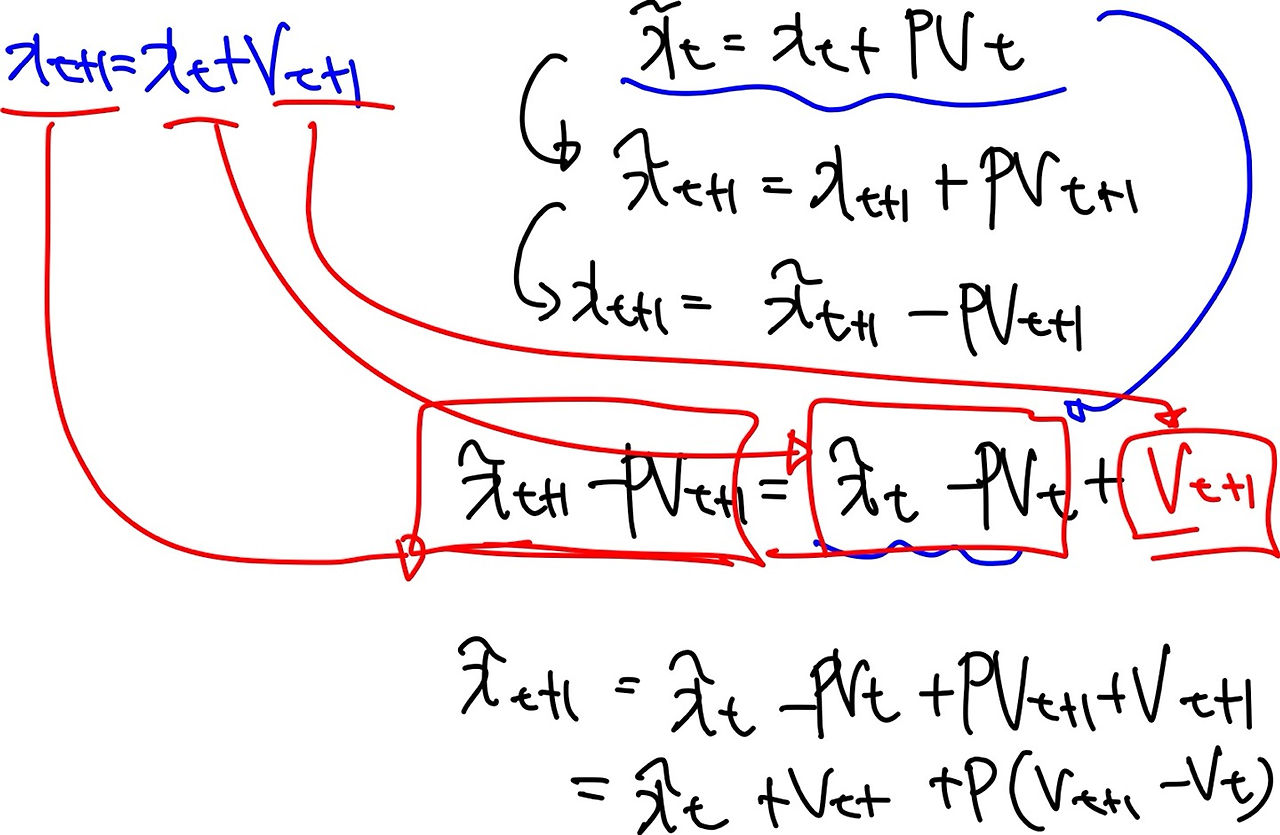
오버슈팅 억제
관성이 커지더라도 오버 슈팅이 될지 미리 살펴보고 교정 → 오버슈팅 억제

한계점
- Netserov는 Convex 최적화에서는 뛰어난 성능을 보임
- NN은 non-Convex 그래프가 더 많다. 따라서 일반적으로 다른 최적화 알고리즘 사용
AdaGrad
- AdaGrad는 손실 함수의 곡면의 변화에 따라 적응적으로 학습률을 정하는 알고리즘
- 손실 함수의 경사가 가파를 때는 작은 폭으로 이동, 경사가 완만하면 큰 폭으로 빠르게 이동
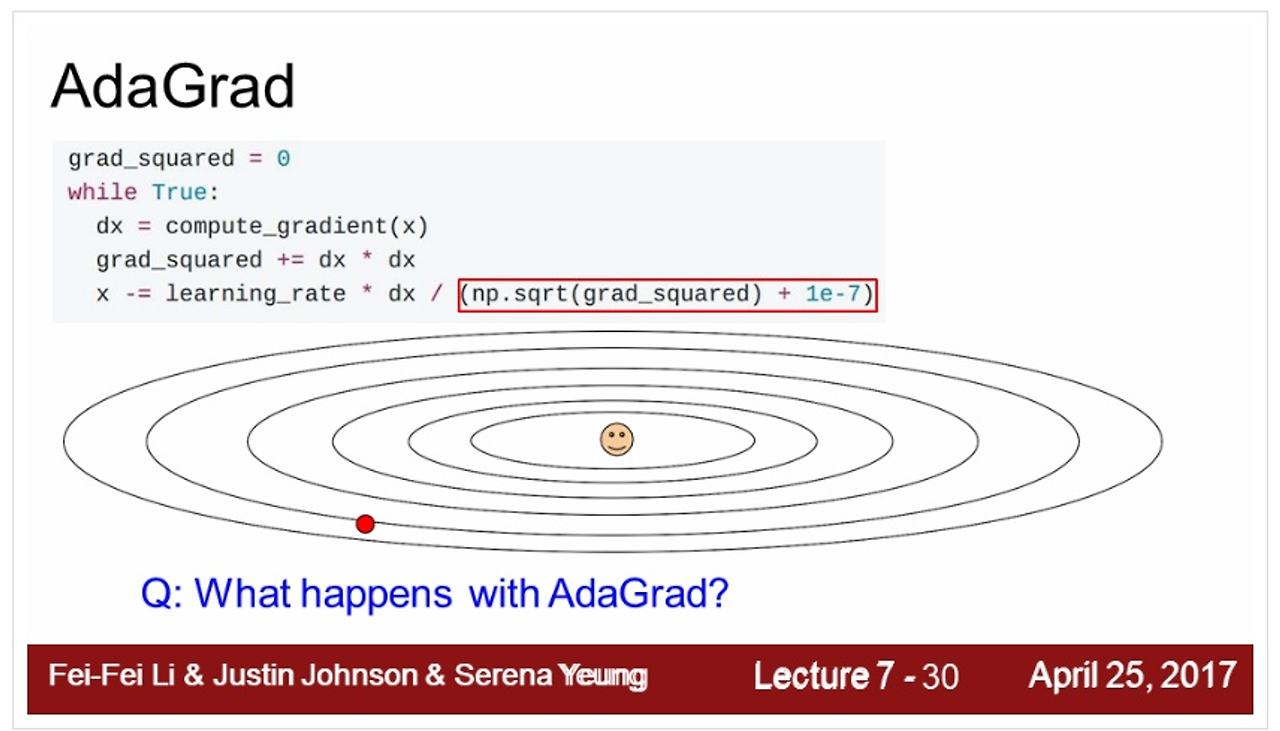
- 모델의 파라미터 별로 곡면의 변화량 계산 → 파라미터 별로 개별 학습률을 갖는 효과
- Adagrad는 Velocity term 대신에 grad squared term 사용 → 기울기 값 이용
- 학습 도중에 계산되는 gradient에 제곱을 해서 계속해서 더해줌
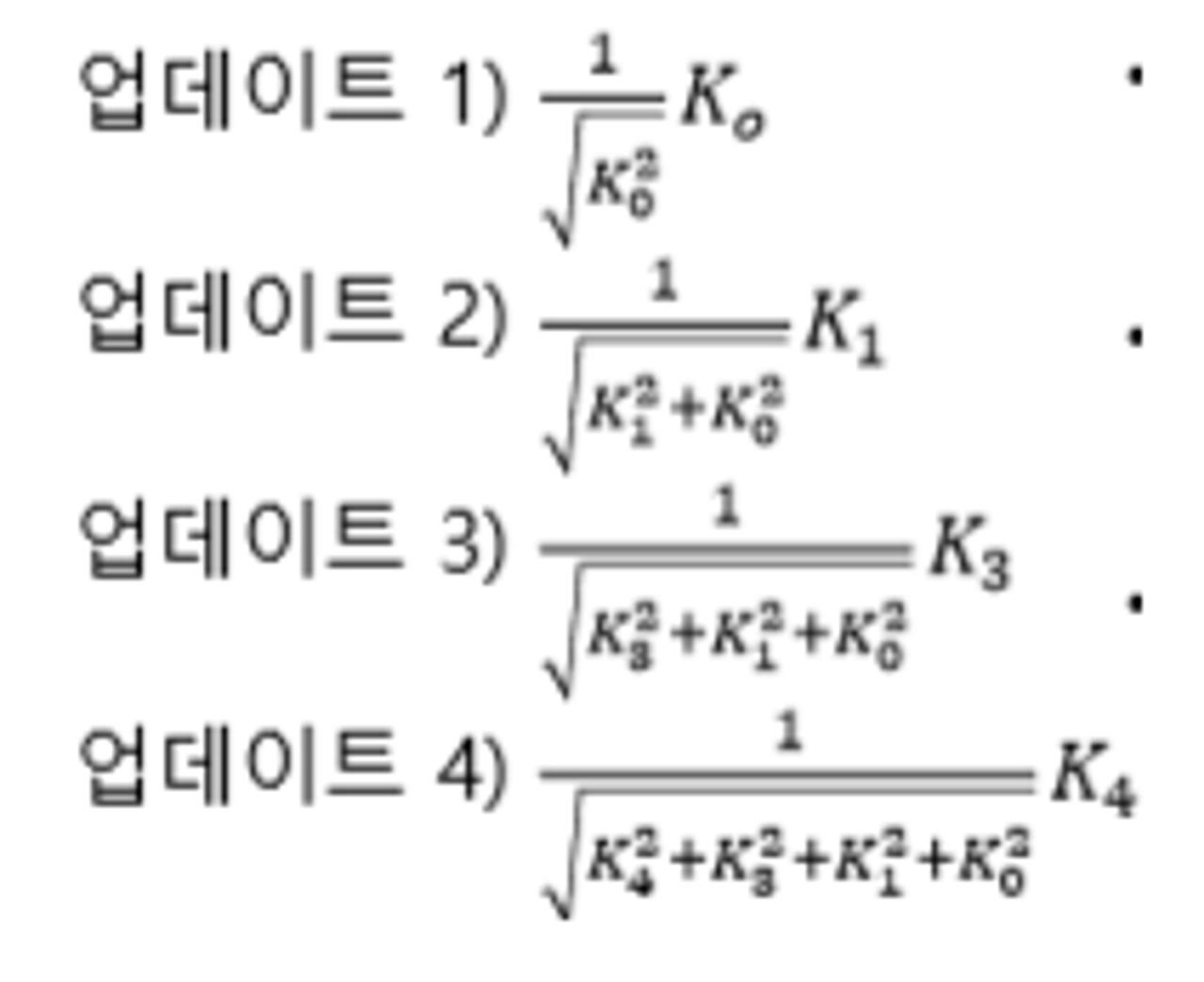
- step을 진행할 수록 값이 작아지게 됨 → 올바른 지점으로 접근할 때 속도가 빨랐다가 점차 느려짐
- 만약 경사가 가파른 위치에서 학습을 시작하면, 초반부터 적응적 학습률이 급격하게 감소해서 조기에 학습이 중단될 수 있음 ← AdaGrad 문제점
RMSProp
- 최근 경로의 변화량에 따라 학습률을 적응적으로 결정하는 알고리즘
- AdaGrad가 가지고 던 초기 학습 중단문제 해결
- 곡면 변화량을 전체 경로가 아닌 최근 경로의 변화량을 측정하면 곡면 변화량이 누적되어, 계속해서 증가하는 현상 없앨 수 있다.
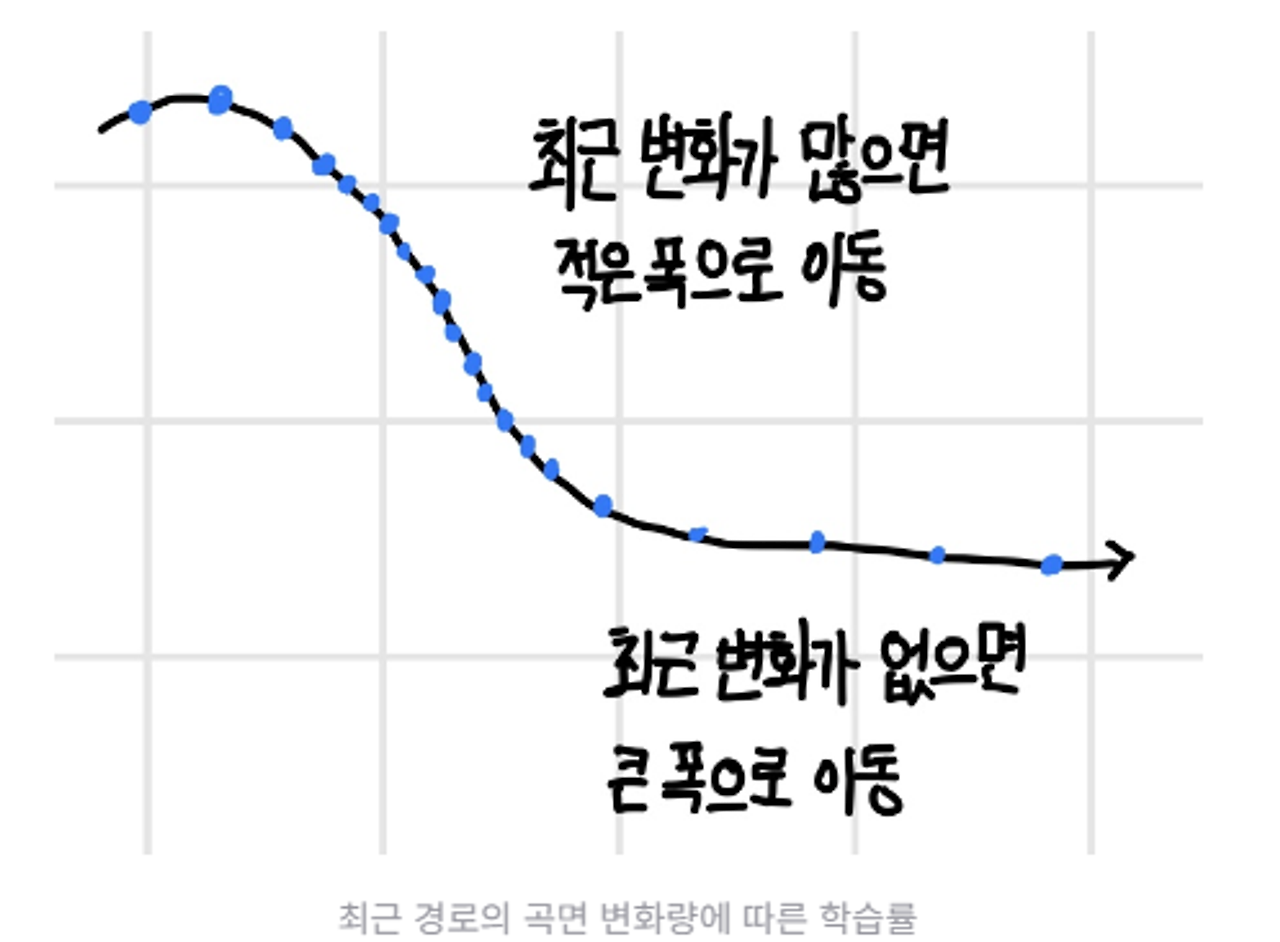
- 지수가중이동편균 활용하여 곡면의 변화량 측정 및 파라미터 업데이트
- 최근 경로의 그레디언트는 많이 반영되고 오래된 경로의 그레디언트는 작게 반영
- 그레디언트 제곱에 곱해지는 가중치가 지수승으로 변화하기 때문에 지수가중평균이라고 함
Adam
- SGD 모멘텀 + RMSProp 결합
- 속도에 관성을 주고 동시에 최근 경로의 곡면 변화량에 따라 적응적 학습률을 갖는 알고리즘
- 초기 편향 문제(첫번째 단계에서 출발 지점으로 부터 멀리 떨어진 곳으로 이동) 해결

- first_moment = 0, second_moment = 0 → 값이 크면 step이 커져서 이상한 곳으로 튈 수 있음 (분자가 커져서)
- 해결 방법 : bias correction term 항 추가, 값이 튀지 않게 방지

step decay learning rate
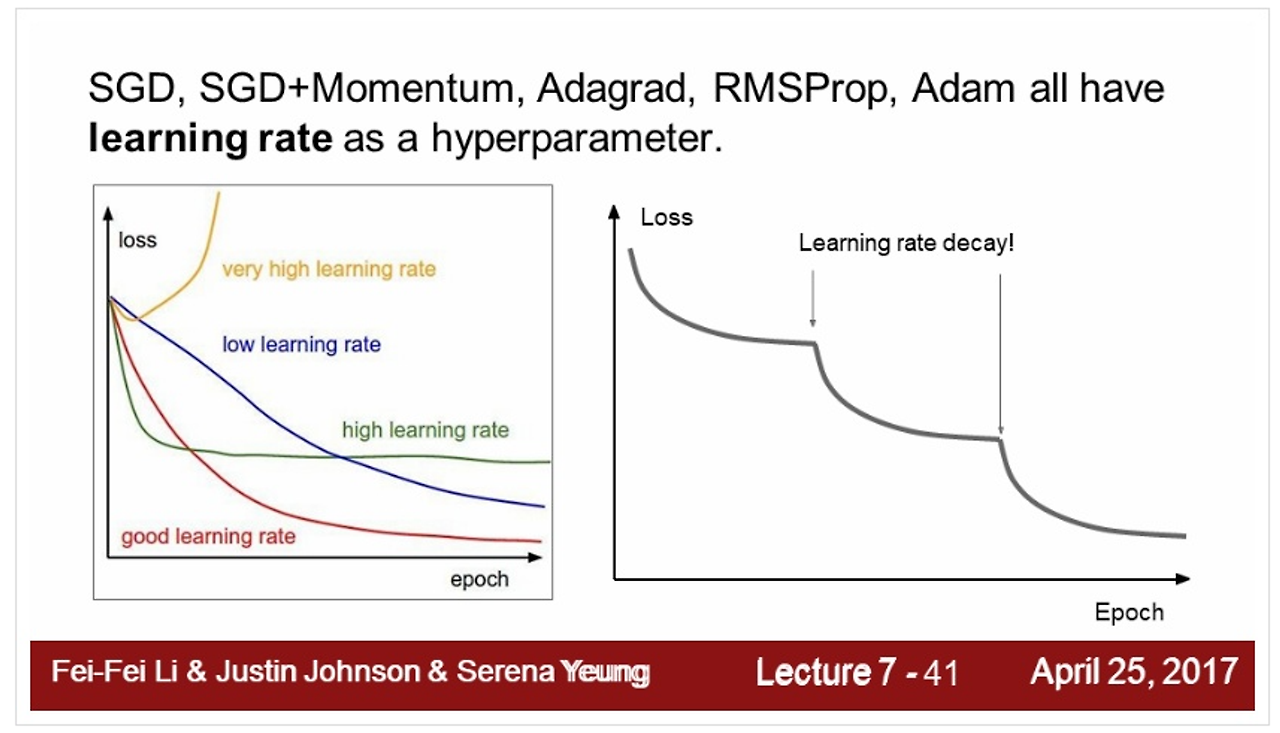
- loss가 내려가다가 평평해지는 구간에 LR(learning rate)를 낮춤
- adam 보다 모멘텀에서 자주 사용
First-Order Optimization & Second-Order Optimization
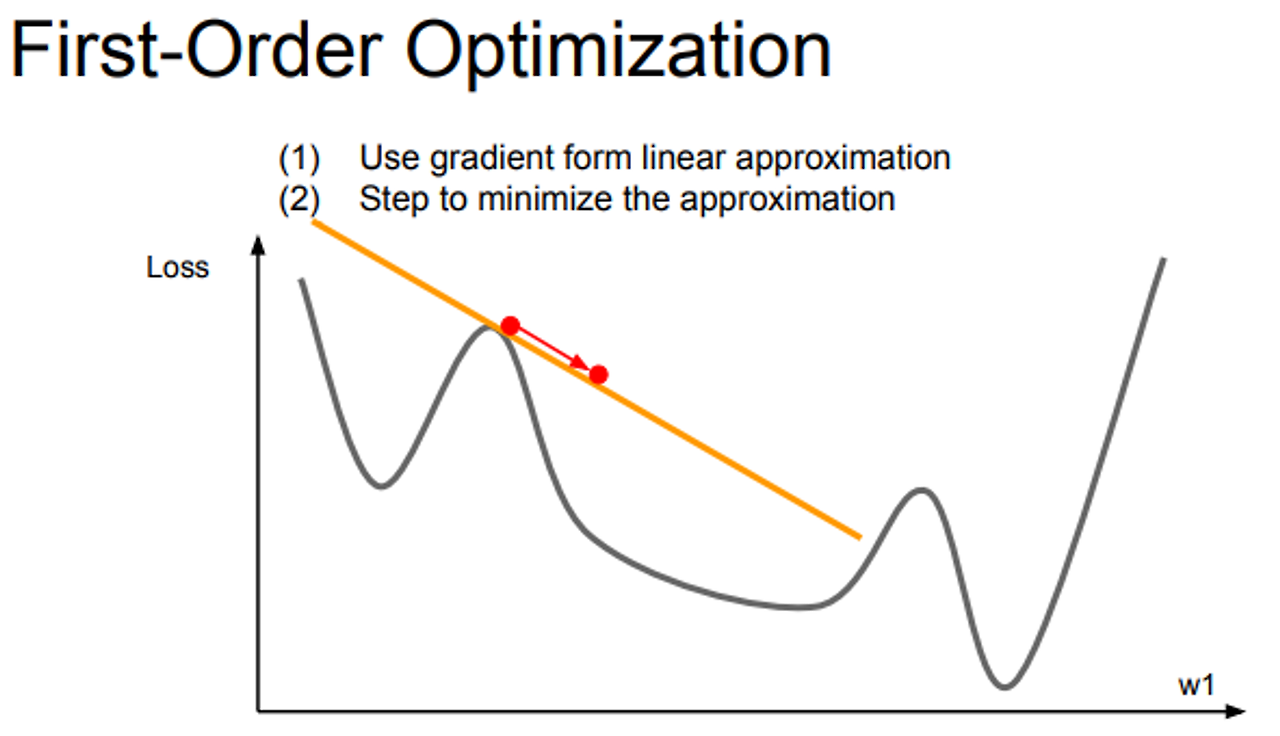
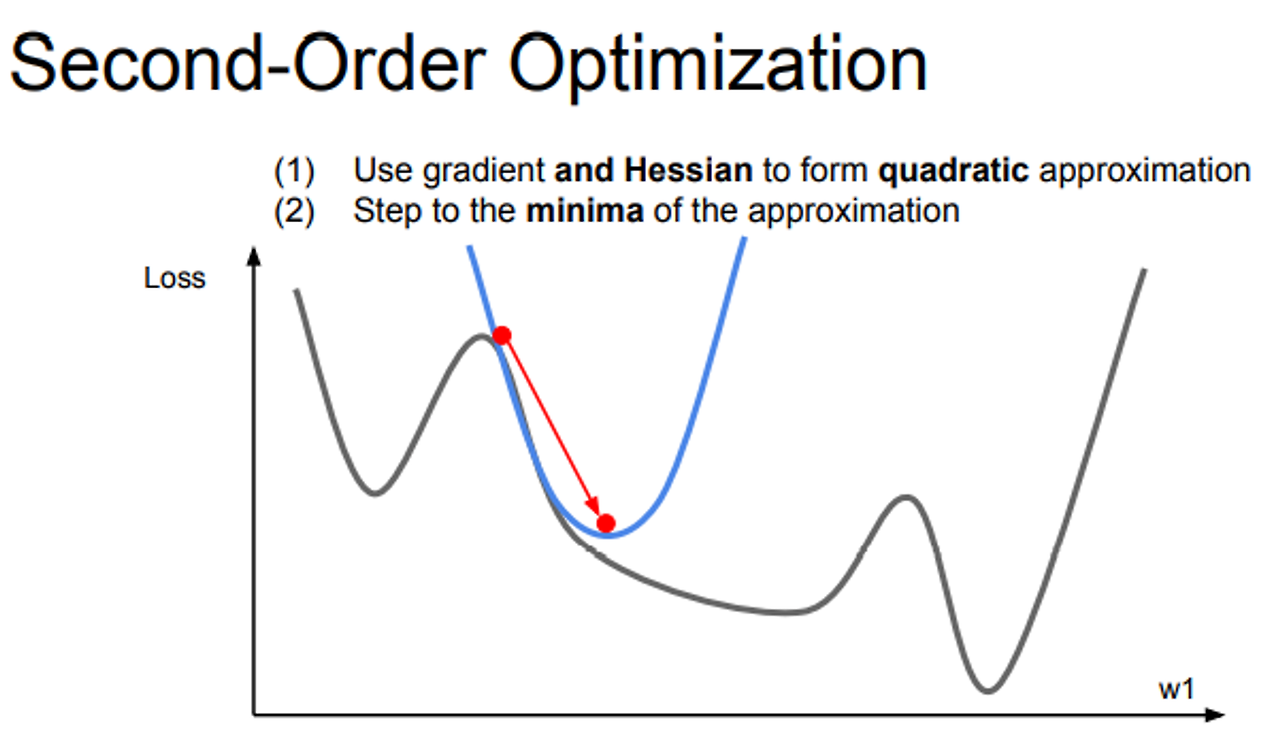
- 지금 까지 1차 근사를 활용하여 최적화 진행
- 2차 테일러 근사 함수에서 Hessian의 역행렬을 이용해서 실제 손실함수의 2차 근사를 이용해 minima로 곧 바로 이동할 수 있음

- 위 방법 활용하면 LR이 필요 없음, 근사함수 만들고, 최소 값으로 이동, 각 step 마다 항상 minima 방향으로 이동
- 하지만 근사가 완벽한 것이 아니기 때문에 LR이 필요하긴 함
- Hessian 행렬이 N*N이기 때문에 연산량이 많아져 메모리 이슈로 딥러닝에서는 사용 x
Model Ensembles
- 모델의 정확도를 높이는 방법
- 여러 모델들을 평균내서 이용 →최종 성능에서 1~2% 성능을 끌어올림 → 경진대회에서 주로 사용
- Learning rate을 낮췄다 높였다를 반복. 손실함수가 다양한 지역에 수렴할 수 있도록 해줌
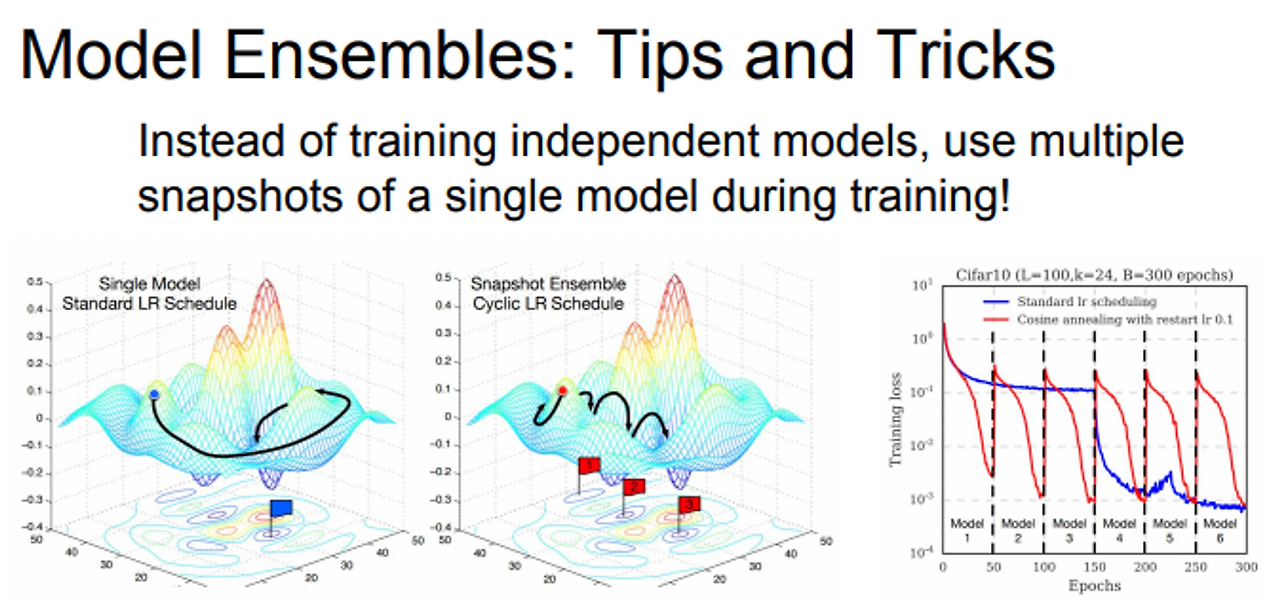
Regularization
- 단일 모델 성능 올리려면 규제를 적절히 사용해야한다
Dropout
- forward pass 과정에서 일부 뉴런을 0으로 만듬. 한 레이어의 출력을 전부 구한 후 일부를 0으로 만듬. fc나 conv에서 사용
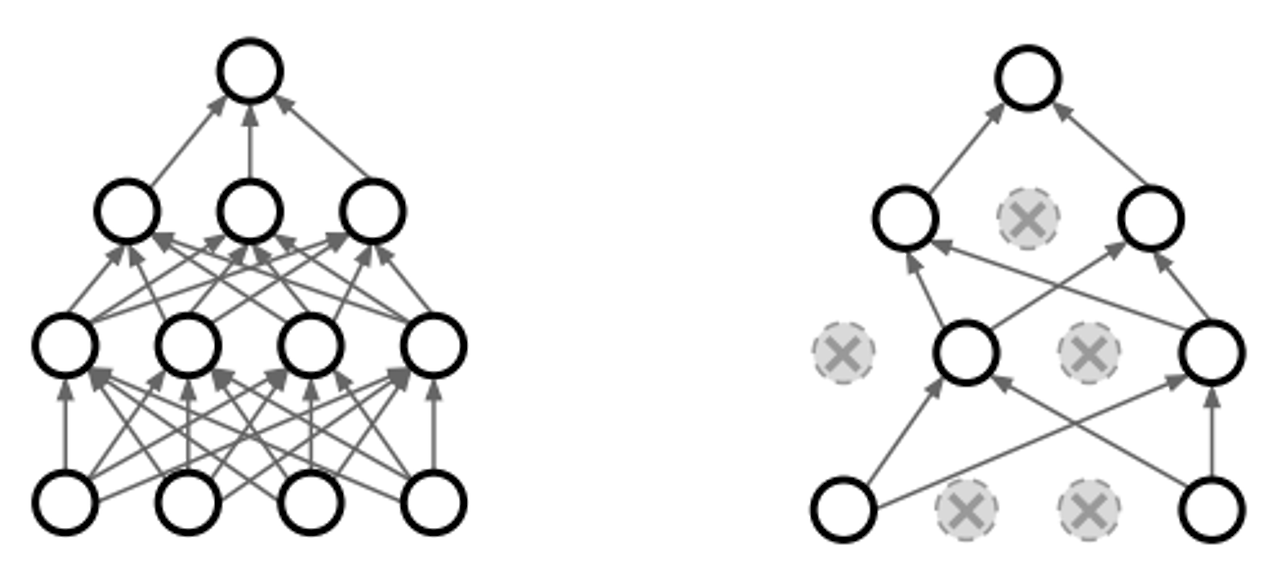
- 네트워크카 특정 피처에만 의존하지 못하게함
- 단일 모델로 앙상블 효과
- dropout을 하면 각 스텝마다 업데이트 되는 파라미터 수가 줄어 학습시간이 늘어나지만 일반화 좋아짐
- Batch Normalization과 유사한 효과
- 랜덤으로 노드를 off
Data Augmentation
- 또 다른 regularization 방법
- Training 할 때, 이미지의 patch를 랜덤하게 훈련 시키거나, 이미지를 뒤집어서 추가해 훈련해주거나. 할 수 있음

Transfer Learning
- 전이 학습이라고도 함, 이미 학습된 모델을 이용하여 우리가 이용하는 목적에 맞게 fine tuning하는 방법
- Small Dataset으로 다시 학습 시키는 경우
- DataSet이 클 경우 좀 더 많은 layer들을 학습 시킨다
- 학습률 낮춰서 사용
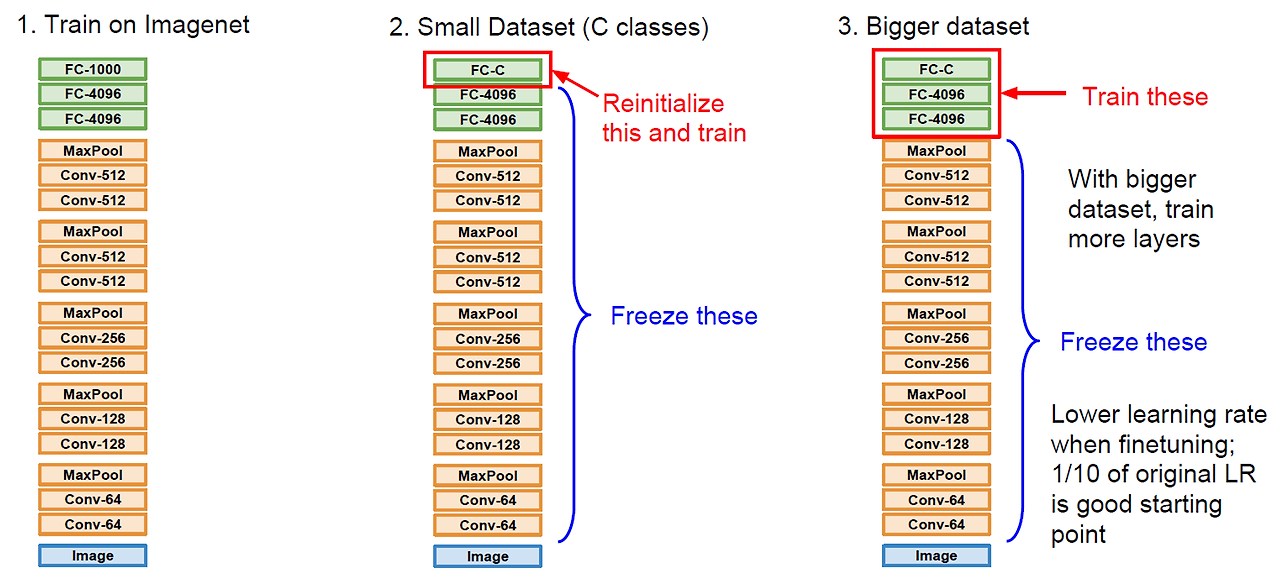
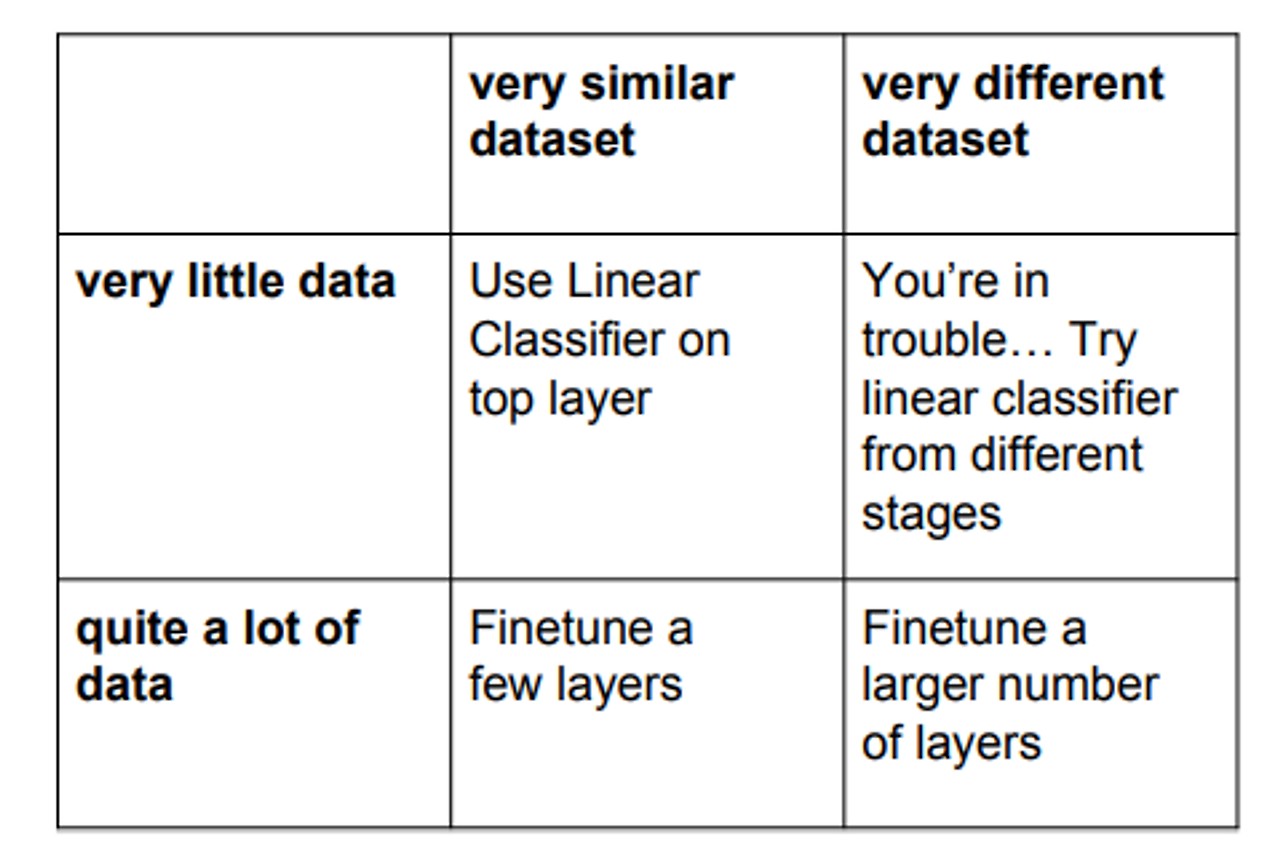
- 4가지의 경우
- 이미 학습한 모델에 레이블이 많이 포함 & 데이터가 작음 → linear Classfier
- 이미 학습한 모델에 레이블이 많이 포함 & 데이터 큼 → fine tune
- 이미 학습한 모델에 레이블이 별로 없음 & 데이터 큼 → Trouble
- 이미 학습한 모델에 레이블이 별로 없음 & 데이터 작음 → fine tune을 크게
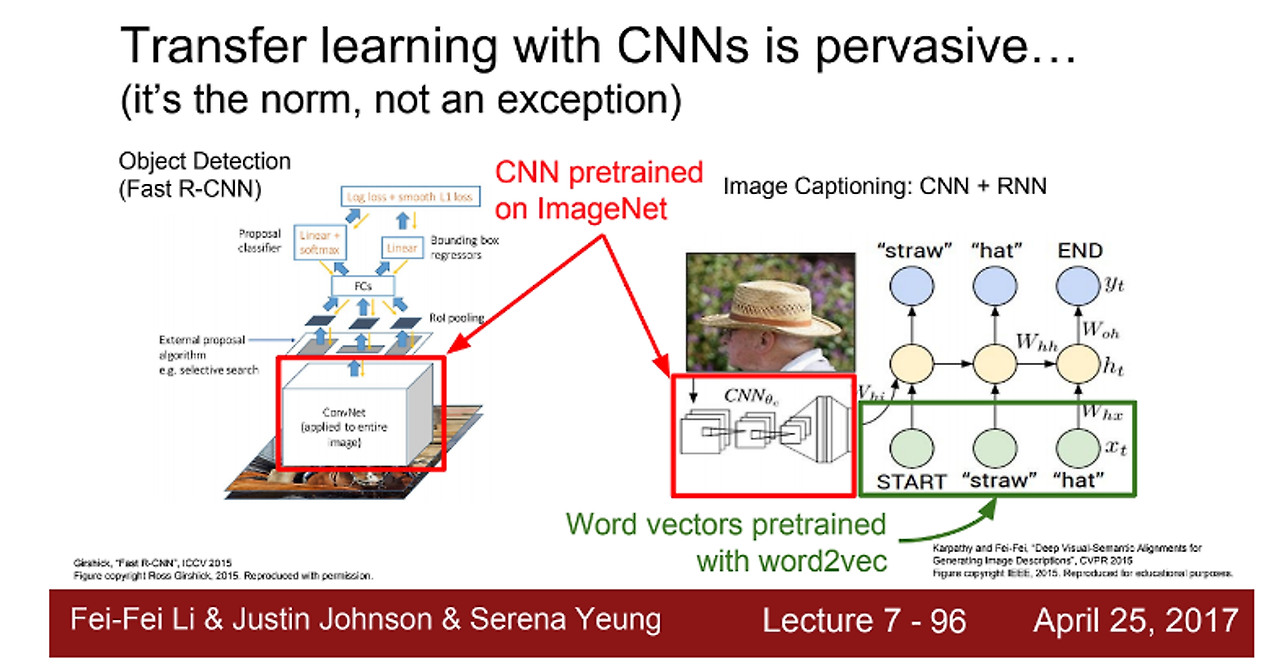
- 전이 학습은 많이 이용됨
- 유사 데이터셋으로 학습된 pretrained model을 이용해서 fine tune 시킴
<Reference>
https://sonstory.tistory.com/70
https://lsjsj92.tistory.com/405
반응형
'Deep Learning' 카테고리의 다른 글
| 윈도우10에 딥러닝 환경 구축의 모든 것.. 이고 싶어요(tensorflow, GPU, CUDA, cudnn) (1) | 2024.06.10 |
|---|---|
| 확률적 경사하강법(SGD), 최적화 (0) | 2024.05.10 |
| [DL] 클러스터링 (0) | 2024.04.25 |
| [DL] L1, L2 규제와 차원 축소 (0) | 2024.04.17 |
| Windows 10에 CUDA, Pytorch 설치하기 (0) | 2024.04.11 |



